Foreword
Machine learning technology provides powerful technical support for many areas of modern society: from web search to content filtering on social networks to product recommendations on e-commerce sites. Machine learning technology is increasingly appearing on consumer products such as cameras and smartphones. A machine learning system can be used to identify objects in an image, convert speech into text, select relevant items of search results, and match news, posts, or other things of interest to the user. There are more and more similar applications, and they all use a technique called deep learning.
Deep learning (also known as deep structure learning, hierarchical learning, or deep machine learning) is an algorithm based on modeling high-level abstractions in data, which is a branch of machine learning. In the simplest case, you can have two sets of neurons: neurons that receive input signals and neurons that send output signals. When the input layer receives the input, it passes the modified version of the input to the next layer. In deep networks, there are many layers between the input and output layers (layers are not made up of neurons, just to help you think), these layers allow the algorithm to use multiple processing layers, which contain multiple linear and non-linear Linear transformation.
Recently, deep learning technology has revolutionized machine learning and has produced many great results. They have greatly improved the techniques of speech recognition, visual object recognition, object detection, and many other areas such as drug discovery and genomics. The term "deep learning" was first introduced into machine learning by Dechter (1986), and artificial neural networks (NN) were introduced by Aizenberg et al. (2000). The further spread of deep learning benefited from the emergence of a convolutional network architecture called "AlexNet" invented by Alex Krizhevsky. "AlexNet" defeated all other image processing algorithms in the 2012 ImageNet competition, pioneering the use of deep learning architecture in image processing.
Deep learning architecture1. A generative depth architecture designed to describe high-order correlation properties of observed or visible data for pattern analysis or synthesis purposes, as well as features describing the joint statistical distribution of visible data and its associated classes. In the latter case, this type of architecture can be turned into a discriminative depth architecture using Bayesian rules.
2. A discriminative depth architecture designed to directly provide discriminative power for pattern classification, usually described by describing a posterior distribution based on the type of visible data.
3. Hybrid depth architecture, the purpose of which is to distinguish, but usually supplemented by the results of a better optimized or regularized generation architecture, or the parameters whose discrimination criteria are used to learn any of the depth generation models in Category 1.
Despite the complexity of the classification of deep learning architectures, deep feedforward networks, convolutional networks, and recurrent networks are often used in practice.
Deep feedforward network
Feedforward networks, often referred to as feedforward neural networks or multilayer perceptrons (MLPs), are typical deep learning modes.
The goal of the feedforward network is to approximate a function f. For example, for a classifier, y=f(x) represents mapping input x to category y. The feedforward network defines a mapping y = f(x; θ) and learns the value of the parameter θ that produces the best approximation function.
In simple terms, a network can be defined as a combination of input, hidden, and output nodes. Data flows in from the input node, is processed in the hidden node, and then produces an output through the output node. The information flows through the function evaluated from x, through the intermediate calculation used to define f, and finally to the output y. There is no feedback connection in the network, where the output of the model is fed back to itself, so the model is called a feedforward network. The model is shown in Figure [1].
![Figure [1]: Feedforward Neural Network](http://i.bosscdn.com/blog/13/5Z/U0/64_0.png)
Figure [1]: Feedforward Neural Network
Convolutional neural network
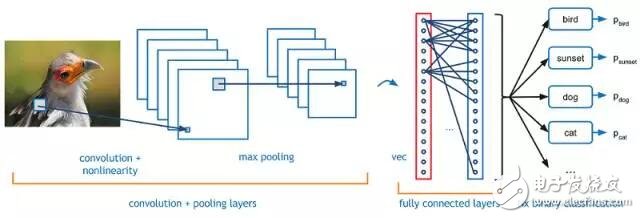
In machine learning, convolutional neural networks (CNN or ConvNet) are feed-forward artificial neural networks whose connection patterns between neurons are invented by animal visual cortical tissue.
The stimuli response of individual cortical neurons to the restricted area is called the receptive field. The receptive fields of different neurons overlap partially, which makes these receptive fields tile like tiles.
The response of a single neuron to the stimulus in its receptive field can be approximated mathematically using a convolution operation. The convolutional network is inspired by biology and is a variant of the multilayer perceptron. It has a wide range of applications in image and video recognition, recommendation systems, and natural language processing.
LeNet is the first convolutional neural network that has driven the development of deep learning. Since 1988, Yann LeCun's groundbreaking work has been successfully iterated into LeNet5. The LeNet architecture at the time was mainly used for character recognition, such as reading zip codes, numbers, and so on.
![Figure [2]: A simple convolutional neural network model](http://i.bosscdn.com/blog/13/5S/VX/9_0.png)
Figure [2]: A simple convolutional neural network model
ConvNet has four main components, as shown in Figure 2:
Convolution layer
2. Activation function
3. Pool layer
4. Fully connected layer
Convolution layer
The convolutional layer is based on the term "convolution", which performs a mathematical operation (f*g) on ​​two variables to produce a third variable. It is similar to cross-correlation. The input to the convolutional layer is an image of mxmxr, where m is the height and width of the image and r is the number of channels, for example, for RGB images, r = 3. The convolutional layer has k filters (or kernels) of size nxnxq, where n is smaller than the dimensions of the image, and q is less than or equal to the number of channels r, and each core can be different.
Activation function
To implement complex mapping functions, a nonlinear activation function is required, which introduces very important nonlinear properties that can be approximated to any function. The activation function is also very important for compressing unbounded linear weighted sums from neurons. This is important to avoid accumulating high values ​​at the processing level. There are many activation functions that are often used, such as Sigmoid, tanh, and ReLU.
Pooling layer
Pooling is a sample-based discretization process. Its goal is to downsample the input representation (image, hidden layer output matrix, etc.), reduce its dimensions, and allow for assumptions about the features contained in the sub-region.
Part of the reason for this is to provide an abstract representation to avoid overfitting. Again, it reduces computational costs by reducing the number of parameters to learn and provides basic transformation constancy for internal representations.
The more prominent pooling technologies are: maximum pooling, minimum pooling and average pooling.
![Figure [3]: Example of maximum pooling of 2*2 filters](http://i.bosscdn.com/blog/13/5P/Mb/1_0.png)
Figure [3]: Example of maximum pooling of 2*2 filters
Fully connected layer
The term "fully connected" means that each neuron in the upper layer is connected to each neuron in the next layer. The fully connected layer is a traditional multilayer perceptron that uses the softmax activation function or any other similar function in the output layer.
Recurrent neural network
In traditional neural networks, we assume that all inputs (and outputs) are independent of each other. But for many tasks, this is a very bad assumption. If you want to predict the next word in a sentence, you'd better know which previous words are. RNNs are called loops because they perform the same task for each element of the sequence, and the output depends on previous calculations. There is also a way to understand RNN, we can think of it as "memory", it will capture all the information calculated so far.
There is a loop in the RNN that allows information to be passed across neurons when reading in the input. In Figure [4], x_t is some input, A is part of RNN, and h_t is output. RNN has some special types, such as LSTM, bidirectional RNN, GRU, and so on.
![Figure [4]: ​​RNN model](http://i.bosscdn.com/blog/13/5I/Ib/4_0.png)
Figure [4]: ​​RNN model
RNN can be used for NLP, machine translation, language modeling, computer vision, video analysis, image generation, image subtitles, etc., because any number of inputs and outputs can be placed in the RNN, and they are one-to-one, many-to-many correspond. Its architecture exists in many forms, as shown in Figure [5].
![Figure [5]: RNN describes the operation of the vector sequence](http://i.bosscdn.com/blog/13/5P/13/5V_0.jpg)
Figure [5]: RNN describes the operation of the vector sequence
applicationThere has been a lot of research in the field of deep learning, and many special problems have been solved using the deep learning model. Here are some great applications for deep learning:
Black and white image colorization
Deep learning can be used to color an image with reference to objects in the photo and its context, just as humans do coloring. This application uses a very large convolutional neural network and supervised layer to reproduce the image by adding color.
machine translation
Text translation can be done without any pre-processing of the sequence, which allows the algorithm to learn the dependencies between words and their mapping to another language. A stacked network of large LSTM cyclic neural networks can be used for machine translation.
Classification and detection of objects in photos
The task is to classify objects in a photo into a known group of objects. In the sample evaluation, very good results can be obtained by using a very large convolutional neural network. The breakthrough results achieved by Alex Krizhevsky and others in the ImageNet classification are called AlexNet.
Automatic handwriting generation
Given a handwritten sample corpus, then generate a new handwriting for a given word or phrase. When the handwriting sample is created, the handwriting is provided to the pen as a series of coordinates. Through this corpus, the algorithm learns the relationship between the movement of the pen and the letters, and then generates a new example.
Automatic game play
In this application, the model will learn how to play computer games based only on pixels on the screen. This is a very difficult task in the field of deep enhancement models, because of this, DeepMind (now part of Google) has earned a high reputation.
Generating model chat robot
Use a sequence-based model to create a chat bot that trains on many real conversation data sets and learns to generate your own answers. For more details, please visit this link.
to sum up
From this paper, we can conclude that the deep learning model can be used for various tasks because it can simulate the human brain. So far, experts have done a lot of research in this area, and there will be a lot of research work to be done soon. Although there is still a problem of trust, it will become more clear in the near future.
Wireless Battery Par Lights Series
It is built with D-Fi transceiver. This wireless battery led light can be controlled by wireless DMX or IR remote controller. It's convenient for home parties, events, and any other places requiring a small fixture lighting up the venue. Shine light where it is needed using the built-in adjustable kickstand and prevent light spillage with the built-in glare shield.
DMX cables can be removed, wireless connection is available without any signal interference. With in-built lion battery, power cables can be removed, each light can be placed seperately without any cable connection, while they are wirelessly connected for the controlling. The charging time is about five hours, while working time reaches 8-12 hours. It is small in size: 15*14*23cm, stuitable for lighting up a truss.
Our company have 13 years experience of LED Display and Stage Lights , our company mainly produce Indoor Rental LED Display, Outdoor Rental LED Display, Transparent LED Display ,Indoor Fixed Indoor LED Display, Outdoor Fixed LED Display, Poster LED Display , Dance LED Display ... In additional, we also produce stage lights, such as beam lights Series, moving head lights Series, LED Par Light Series and son on...
Wireless Battery Par Light Series,Beam 230 7r,Stage Beam Light,Moving Head Stage Lights
Guangzhou Chengwen Photoelectric Technology co.,ltd , http://www.cwstagelight.com