Application of Image Processing Technology in License Plate Recognition
Using digital image processing technology to research and develop the automatic recognition system of automobile license plate. Determine the position of the license plate from the car image, extract the microstructure characteristics of the license plate characters, and obtain the license plate number by matching and comparing with the standard template of the characters in the built special dictionary library. The test results show that the scheme is effective.Keywords: digital image processing character recognition license plate recognition classification matching
The automatic license plate recognition system can recognize the input car image through processing and output it as a few bytes of license plate character string, which has unparalleled advantages in terms of storage space occupation and connection with the management database. In the large parking lot, the traffic department's violation monitoring (electronic police), highway and bridge toll station management, etc., have wide application prospects.
1 License plate positioning and pretreatment
After inputting the car image file in Raw format file to the computer, the computer extracts the license plate part from the whole image to realize the license plate positioning. Set the threshold to 127 and the detection threshold to 16. Then scan the image line by line from top to bottom.If the number of 0 → 1 and 1 → 0 changes of a line is greater than the threshold, it is assumed to be the lowest point of the license plate to be tested and continue to scan line by line until 0 → 1 and 1 → 0 The case where the number of changes is less than 8 occurs. Assume this value as the highest point of the license plate to be tested. If the difference between the highest point and the lowest point is greater than 15, it is considered that the target has been detected, otherwise continue to scan. If no target that meets the above conditions is detected, the threshold is automatically adjusted to repeat the above operation. Until the goal is found.
Using the projection of the binary image in the vertical direction as a feature, the coordinates of the center point of the target are searched from left to right. Examine the previously obtained target height as the sum of the vertical projections in the square window with side lengths (that is, the number of pixel points that contain a pixel value of 1), if the value is less than the empirical threshold (after multiple tests The threshold is taken as 150), it is regarded as the background part without text information. If the value is greater than the threshold for the first time, it is regarded as the left boundary part of the license plate to be recognized; The horizontal coordinate of the midpoint of the window is the target center point. Taking the target center point as the reference to the right, the window with the height as the obtained target height and the width of 30 again counts the number of pixel points with a pixel value of 1, if the value is less than the empirical threshold of 16 for the first time, it is regarded as reaching the target The boundary, and take the coordinates of this point as the coordinates of the rightmost point of the target. The determination of the coordinates of the leftmost point of the target is similarly available.
Since the aspect ratio of the license plate is fixed, it is used as a target evaluation standard, considering the deformation factors. If the aspect ratio is not within the range (0.2 ~ 0.6) ?, it is regarded as an invalid target. The threshold is revised and the cycle begins. Finally reached the border.
Target image preprocessing includes image smoothing, character and background separation, range adjustment, and tilt correction. 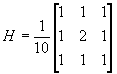
According to the actual situation, the eighth neighborhood average method is used for image smoothing. The mask used is:
The thresholding algorithm used to achieve the separation of characters and background is to store the number of pixels in the target image with all gray values ​​of i in the one-dimensional integer array element A [i]? With 256 elements. The comparison results in the gray value a with the highest probability in the target image. The study found that there are two different situations,  As shown in Figure 1 and Figure 2, respectively.
As shown in Figure 1 and Figure 2, respectively.
For the first case, the image information is mainly located in the gray interval (0 ~ a), then find the gray interval (0 ~ b), so that the number of pixels in the interval accounts for the total pixels of the target image 30% of the number of points. Take b as the threshold value, so that the pixel points whose gray value is greater than the threshold value are 0, and the pixel points in other cases are 1. Treat the second case in the same way. From left to right, the target image is scanned with a detection window of the same height and width of 30 as the target image. Investigate its pixel density, and stop scanning when the number of pixel points with value 1 is less than 50%. Take the left coordinate of the detection window at this time as the left boundary of the target. The right border of the target is similarly available. According to the range information of the obtained license plate image, if necessary, tilt transformation is performed by rotation transformation.
 2 Automatic single character column segmentation
2 Automatic single character column segmentation
Column segmentation is to divide the license plate image extracted after positioning into single character images. The projection of the character block in the vertical direction must achieve the local minimum at the correct segmentation position (ie, the character or the gap within the character), and this position should meet the writing rules and character size restrictions. Project the character image vertically. Detect the projected value of each coordinate in the horizontal direction from left to right. The coordinate detected that the first projection value is not 0 can be regarded as the left boundary of the first character, and the coordinate detected with the first projection value of 0 from the coordinate to the right can be regarded as the right boundary of the first character, and the boundary coordinates of the remaining characters The same is true.
By the average character width of the character and the average distance between the left borders of the two characters, possible erroneous points can be removed. Characters whose word width is less than a certain proportion of the average word width (such as 0.2) are considered invalid characters; the distance between the two characters before and after the distance is less than the average distance and the sum of this distance and the word width is not greater than the average distance, then merged into one character; for the word width A certain percentage of the average character width (such as 2.4) is regarded as the occurrence of two characters.
After the above processing, accurate segmentation results can be obtained. Transform characters into 64 × 64 lattice space to facilitate subsequent processing such as feature extraction.
3 Outline and refine
The contour processing adopts the four-neighborhood method. For the 64 × 64 text image F (i, j) smoothed by noise, the four adjacent points of the black pixel point (i, j)? Are scanned. , As long as one point is not black, the point (i, j)? Is the point on the outline of the character, and its gray level is set to 1 (that is, black), otherwise the gray level of the point (i, j) is 0 ( That is white). The thinning process uses the second scan thinning method, which is faster, but because it is a relatively simple iterative algorithm, it sometimes causes a certain degree of skeleton deformation.
 Figure 3 (b) and Figure 3 (c) give the results after contouring and thinning, respectively.
Figure 3 (b) and Figure 3 (c) give the results after contouring and thinning, respectively.
4 Extraction of microstructure features
The characters are divided into n × n networks, and the direction characteristics of regional strokes are counted for each small network. Each small area highlights the local characteristics of the character and is insensitive to small deviations or deformations. The two line elements formed by three adjacent points are defined as microstructures. Outlined characters, including twelve kinds of boundary line elements and character pens 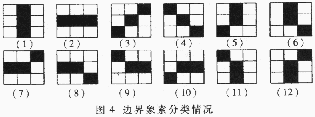 Plan related (as shown in Figure 4).
Plan related (as shown in Figure 4).
According to the four basic directions of the character strokes, the horizontal, vertical and ± 45 ° line element directions can be defined accordingly. And can count the area stroke direction density vector.
Divide the 64 × 64 characters to be recognized into a 5 × 5 grid, the size of the first 4 × 4 grid is 13 × 13, the last row and column of grids are 12 × 12 except the last one, and the last line is 12 × 13, The last column is 13 × 12, and the stroke direction feature vector is counted, so that a four-dimensional direction feature of horizontal, vertical, + 45 °, and -45 ° is obtained in each region, which constitutes the 100-dimensional classification feature of the entire character.
The stability of the extracted features is crucial to the recognition accuracy, so the characters are divided into 8 × 8 and 7 × 7 in fine classification. Count the 64 + 49 = 113 small area regional stroke direction vectors (a total of four directions) to form 113 × 4 = 452-dimensional fine classification features. The 8 × 8 segmentation is used to extract finer structural features in a smaller area. In order to prevent the instability of the segmentation edge, a 7 × 7 double segmentation was performed, so that the original most unstable 8 × 8 grid edge stroke is located in the central most stable area of ​​the 7 × 7 grid, which improves the area edge stroke stability.
5 matching strategy
In order to improve the accuracy and speed of recognition, a multi-level classification recognition scheme is used in matching.
In the rough classification, a simple regional stroke direction feature is adopted, and the characters are divided into a 5 × 5 grid (a total of 25 small areas), and the four directional characteristics of line elements are counted to form a 100-dimensional (25 × 4) feature vector. Use the absolute value distance criterion. Let any feature vector in the dictionary library be 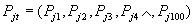 , The feature vector of the character to be recognized is
, The feature vector of the character to be recognized is 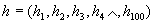 , The distance between any template in the dictionary and the character to be recognized is dj.
, The distance between any template in the dictionary and the character to be recognized is dj.
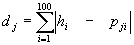
Select the first 10 characters with the smallest value in dj as the result of preliminary matching, and enter the next step for fine classification.
In the fine classification, the 452-dimensional feature vectors are extracted as the features of the fine classification by double segmentation of the candidate characters. The second matching is carried out with a similar criterion as the rough classification. The parameters are determined through experiments, different weight coefficients and rough classification criteria are combined to determine the matching degree of the characters to be recognized and different standard templates, the first four are taken as the final results and output to the specified text file.
6 Establishment of a standard dictionary library
The font is selected from many fonts. Chinese characters are selected from the Song font, and letters and numbers are selected from the OCR-A font. The standard characters are normalized, outlined and feature extracted respectively. The standard template is the feature vector obtained from the feature extraction.
7 Test results
The license plate positioning is very ideal; the characters are segmented correctly; the recognition of the first characters of Chinese characters is sometimes misrecognized (it is difficult to recognize Chinese characters, and the establishment of matching algorithms and template libraries is the key to the problem); the recognition of letters and numbers Better; reach 100% in the first two levels of fine classification priority
Robot Vacuum Cleaners With Mopping
Robot Vacuum Cleaners With Moppin,Robot Vacuum Cleaner With Bluetooth ,Robot Vacuum Cleaner With Gyroscope,Cleaner Robot Ultrasonic Cleaner
NingBo CaiNiao Intelligent Technology Co., LTD , https://www.intelligentnewbot.com