Designing complex broadband wireless system receivers using Xilinx Virtex-5 devices with AutoESL advanced synthesis tools offers a powerful approach to implementing high-performance communication systems. These systems are essential for modern wireless applications, where the demand for higher data rates and improved spectral efficiency is ever-growing.
Space division multiplexing (SDM) combined with MIMO processing technology has emerged as a key enabler in next-generation wireless systems like WiMAX and OFDM-based networks. By utilizing multiple antennas at both the transmitter and receiver, SDM significantly enhances the capacity of wireless channels without requiring additional spectrum. This makes it a crucial component in the evolution of high-speed wireless communication standards.
One of the most challenging aspects of MIMO systems is signal detection, particularly in high-order modulation schemes. Sphere decoding is an advanced technique that provides near-optimal performance in terms of bit error rate (BER), comparable to maximum likelihood (ML) detection. However, traditional digital signal processors (DSPs) lack the computational power needed to handle real-time sphere decoding due to its high complexity.
Field Programmable Gate Arrays (FPGAs) offer a compelling alternative for implementing computationally intensive algorithms such as sphere decoding. Modern FPGAs provide high parallelism and reconfigurable hardware, making them ideal for real-time signal processing tasks. Compared to conventional DSPs, FPGAs can deliver up to 100 times better performance while offering greater flexibility and scalability.
Despite these advantages, FPGAs have not been widely adopted in wireless signal processing due to the complexity of hardware design. Traditional design methodologies require deep knowledge of hardware description languages (HDLs) like VHDL and Verilog, which can be a barrier for many software engineers. However, recent advances in high-level synthesis tools, such as AutoESL's AutoPilot, are changing this landscape by enabling algorithmic descriptions to be directly translated into efficient hardware implementations.
Using AutoESL’s AutoPilot tool, we implemented a space division multiplexing MIMO sphere detector under the 802.16e standard on a Xilinx Virtex-5 FPGA operating at 225 MHz. This approach significantly reduces development time and improves design quality by abstracting the complexities of low-level hardware design.
Sphere Decoding
Sphere decoding is a critical part of the MIMO detection process, offering a balance between performance and computational complexity. It provides BER performance close to that of maximum likelihood detection but with much lower complexity. This makes it a preferred choice in high-throughput wireless systems.
As shown in Figure 1, the block diagram of the MIMO 802.16e radio receiver includes several key stages: channel reordering, QR decomposition, and the sphere detector. Soft outputs from the sphere decoder are generated using log-likelihood ratios (LLRs), which are then used by soft-input, soft-output decoders such as turbo decoders.
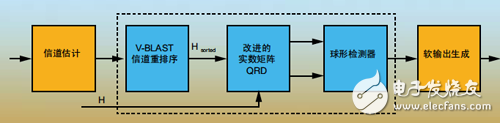
Figure 1: Block diagram of the sphere decoder
Channel Matrix Reordering
The order in which the sphere detector processes the received signals plays a significant role in overall system performance. Channel matrix reordering is performed before sphere detection to optimize the detection sequence. This technique is similar to interference cancellation methods used in the BLAST architecture, allowing the system to achieve near-ML performance with reduced complexity.
The reordering process involves multiple iterations to determine the optimal column ordering of the channel matrix. During each iteration, the row with the smallest or largest Euclidean norm is selected. The smallest norm corresponds to the strongest channel, while the largest norm represents the weakest. This method ensures that weaker signals are processed first, followed by stronger ones in subsequent iterations.
To meet the high data rate requirements of the 802.16e standard, we implemented a pipelined channel ordering module capable of processing five channels simultaneously in Time Division Multiplexing (TDM) mode. This architecture allows for efficient resource utilization and maintains high throughput by extending processing times between different matrix elements on the same channel.
In Figure 2, the G matrix calculation is one of the most computationally demanding parts of the algorithm. At the core of the process is matrix inversion, typically achieved through QR decomposition. A common implementation of QRD uses Givens rotation, which is well-suited for parallel processing on FPGAs.
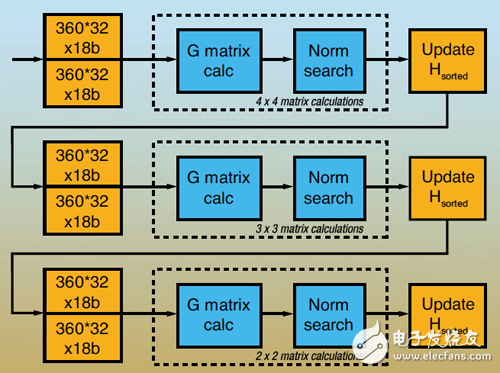
Figure 2: Iterative channel matrix reordering algorithm
This algorithm performs complex rotations on diagonal and non-diagonal elements, which serve as the fundamental building blocks of the pulsating array used in our design. Once the channel matrix columns are optimally ordered, the next step is to perform QR decomposition on the real matrix coefficients. The functional unit for this QRD processing is similar to the QRD engine used for inverse matrix computation, though it handles real numbers instead of complex values. As a result, the pulsating array structure is expanded to accommodate 8x8 real values instead of 4x4 complex values.

A solar cell panel, solar electric panel, photo-voltaic (PV) module, PV panel or Solar Panel is an assembly of photovoltaic solar cells mounted in a (usually rectangular) frame, and a neatly organised collection of PV panels is called a photovoltaic system or solar array. Solar panels capture sunlight as a source of radiant energy, which is converted into electric energy in the form of direct current (DC) electricity.
60w Solar Panel,Solar Panel System For Home,Solar Panels 200 Watt,Solar Panels
suzhou whaylan new energy technology co., ltd , https://www.xinlingvideo.com