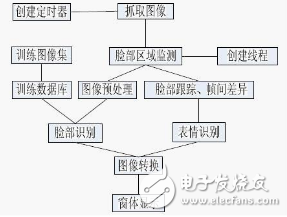
After the face test mentioned earlier, the face is extracted and saved for training or recognition. The code for extracting the face is as follows:

Face Preprocessing
Once you have a face image, it can be used for face recognition. However, if you try to use an unprocessed image directly, you may lose up to 10% of accuracy! This is because most face recognition algorithms are highly sensitive to lighting, pose, and other variations. If you train in a dimly lit room, your system might fail to recognize someone in bright light.
To address this, preprocessing is essential. It helps standardize the input images so that the recognition algorithm can work more effectively. Some key preprocessing steps include adjusting brightness and contrast, aligning the face, removing background noise, and ensuring consistent size and orientation. These steps help reduce variability caused by different environments and improve overall performance.
For simplicity, the face recognition system we’re using here relies on grayscale images. I’ll show you how to convert a color image to grayscale and apply histogram equalization to enhance brightness and contrast automatically. For even better results, you could explore color-based methods like using HSV instead of RGB, or apply additional techniques such as edge detection, contour analysis, or motion filtering.
PCA Principle
Now that you have a preprocessed face image, you can proceed with face recognition using Principal Component Analysis (PCA). OpenCV provides the cvEigenDecomposite() function for PCA operations, but you need a training dataset to teach the system how to identify faces.
To build a training set, collect multiple preprocessed images of each person. For example, if you're trying to recognize 10 people, you might store 20 images per person, totaling 200 images of the same size (e.g., 100x100 pixels).
The eigenface method, explained in several articles, uses PCA to transform the training images into a set of "feature faces." These feature faces represent the main variations between the images. The process starts by computing an average face, then calculating the principal components—each representing a major variation in the dataset.
The first few feature faces often highlight significant facial features, while later ones may contain more noise. In practice, only the top 30–50 feature faces are typically used, as they capture most of the variation without introducing unnecessary complexity.
Each training image can be represented as a linear combination of the average face and the feature faces. For instance, a training image might be expressed as:
(averageFace) + (13.5% of eigenface0) – (34.3% of eigenface1) + (4.7% of eigenface2) + ... + (0.0% of eigenface199)
This gives a set of coefficients that uniquely describe the image. When recognizing a new face, the same PCA process is applied, and the resulting coefficients are compared to those in the database to find the closest match.
Training Data
Creating a face recognition database involves compiling a text file that lists the image files and the corresponding person’s name. For example, a file named trainingphoto.txt might look like this:
Joke1.jpg
Joke2.jpg
Joke3.jpg
Joke4.jpg
Lily1.jpg
Lily2.jpg
Lily3.jpg
Lily4.jpg
This tells the program that “Joke†has four images and “Lily†has four as well. The loadFaceImgArray() function can then load these images into an array.
To create the database, use OpenCV functions like cvCalcEigenObjects() and cvEigenDecomposite(). These functions compute the eigenfaces and prepare the model for recognition. The cvCalcEigenObjects() function takes parameters like the number of objects, input images, output feature faces, and other settings to generate the principal components.
oxides, nitrides, silicides, borides, and carbides
Yixing Guangming Special Ceramics Co.,Ltd , https://www.yxgmtc.com